Apache Spark: Architecture and Application Lifecycle
Written By:(Bilal Maqsood Senior Consultant Data & AI Competency)
August 11, 2021
Apache Spark is an open-source distributed data processing engine. It is fast due to its in-memory parallel computation framework. Spark was developed in 2009, and since then, it has been rapidly adopted by enterprises like Netflix, Uber, eBay, etc. Today, Spark is considered a key component in any BigData ecosystem. In this article, we will cover the following aspects:
- Spark’s basic architecture
- Transformations and actions
- Spark’s application lifecycle
Basic Architecture
A typical Spark application runs on a cluster of machines (also called nodes). It breaks extensive tasks into multiple smaller ones and distributes them among these machines. However, this creates a challenge to coordinate and manage work across these machines. Spark has this functionality built into it, and its architecture is designed to handle large distributed applications. There are several core components and roles assigned to these that help execute this distributed work.
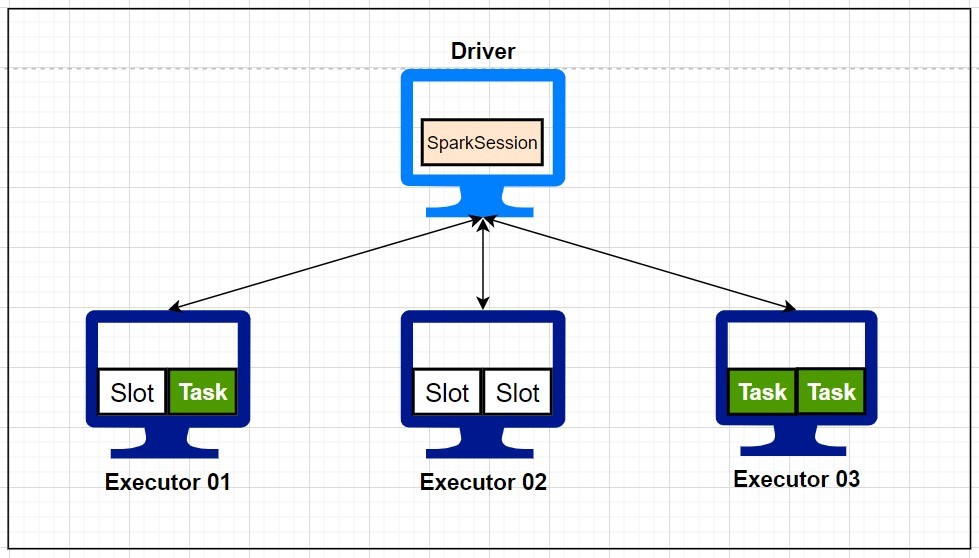
Figure 1: Spark Application Architecture
Figure 1 shows the architecture of the Spark application. These components are discussed below.
Driver
The driver (or driver program) is a process running on one of the machines in the cluster. It is responsible for the complete lifecycle of the Spark application and maintains the information about the Spark application. It analyses, distributes, and schedules tasks (processing to be done) on executors (worker machines). It also responds to a user after the success/failure of the application. A driver is analogous to an orchestrator. Like an orchestrator, the driver doesn’t perform any computations. It just manages the overall application lifecycle (Figure 1).
Executors
Executors are the worker processes that run on other machines in the cluster. There can be multiple executors running on the same machine. Each executor has a collection of data— also called partition — that they execute code on, as assigned by the driver. They also report the state (success/failure) of assigned work back to the Driver (Figure 1).
Slots
Each executor can have multiple slots available for a task (as assigned by the driver) depending upon the cores dedicated by the user for the Spark application. This means that there are two levels of parallelism: First, work is distributed among executors, and then an executor may have multiple slots to distribute it further (Figure 1).
Tasks
A task is a work to be done on a partition (collection of rows). These are assigned by the driver to executors. These will run in the slots available on executors (Figure 1). A worker machine in the cluster can have multiple executors running on it. Each executor can have multiple slots available for task execution.
Jobs
A job is a parallel action in Spark. A spark application — maintained by the driver — can contain multiple jobs.
SparkSession
The SparkSession is a Driver process that controls your Spark application. It is the entry point to all of Spark’s functionality. For notebooks and REPL environment, it is already created under the variable “spark” (Figure 2). However, when writing applications, you have to create SparkSession yourself, as shown below.
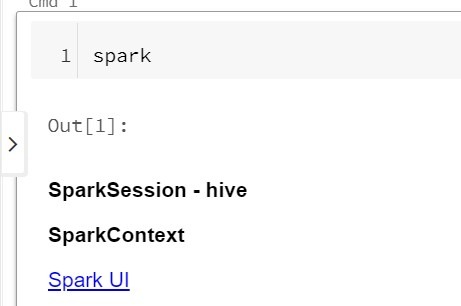
Figure 2: SparkSession found as Spark in Databricks notebook
## Create a SparkSession when building applications
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local")\
.appName("My First App")\
.config("config.name","config.value")\
.getOrCreate()
After creating SparkSession, you will be able to run PySpark code. SparkSession was added in the Spark 2.x version. We have two different contexts in earlier versions: SparkContext and SQL context, which provided functionality for interacting with RDDs and Dataframes/Hive, respectively. Both of these functionalities have now been merged into SparkSession; however, SparkContext and SQL Context have not been deprecated yet and can still be accessed individually (Figure 3).
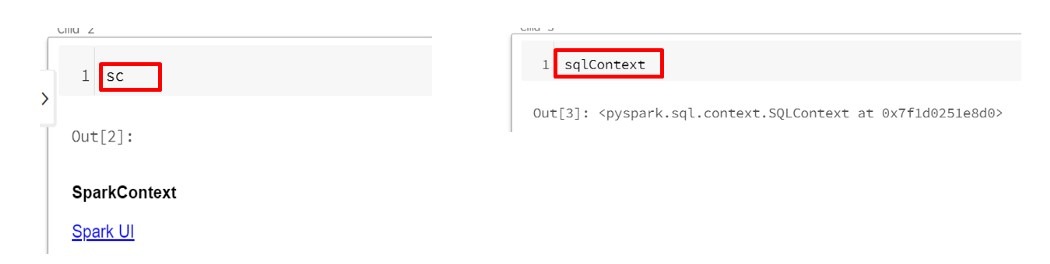
Figure 3: SparkContext and SQLContext
Transformations, Actions, and Execution
Transformations are the functions that help you implement the logic. One can use these to modify underlying data. Examples of transformations are select, filter, groupBy, orderBy, limit , etc. Transformations are lazy in nature, which means the processing is not performed until an action is called. Spark just builds a lineage and waits for an action to be called to execute transformations in that lineage (Figure 4). Lazy evaluation makes it easy to perform operations in parallel and allows for various optimizations.
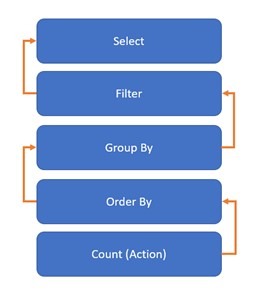
Figure 4: Spark Lineage
Transformations can be narrow or wide. Narrow transformations do not incur a shuffle (movement of data among machines over a network), i.e., data required to compute the result resides on at-most one partition. On the other hand, wide transformations cause a shuffle as the underlying data resides in many partitions and is required to be re-distributed across machines.
Actions
Actions are the statements that, when encountered, trigger the computation from the lineage. While transformations are lazy in nature, actions are eager. Examples of actions are show(), count(), collect() etc.
- data_file= spark.read.csv(“/home/users/some_random_data.csv”)
- selection_df= data_file.select(“first column”, “second column”)
- filter_df= selection_df.where(“second column is not NULL”)
- group_df= filter_df.groupBy(“first column”)
- count_df= group_df.count()
The above code example shows a typical spark application. For steps 1–4, we are reading data from a CSV file and applying a bunch of transformations. Spark is only building a lineage in memory for these steps, and no actual processing is performed. Step 5 is a count() Action. When Spark reaches this point, it traces the lineage back to step 1, performs all the processing, and outputs the total count
Pipelining
Whenever a shuffle is encountered in a Spark application, data is written to executor disks. However, all the steps before the shuffle operation can be clubbed together and performed at once. This is called pipelining, and it makes queries even faster combined with the fact that Spark does its processing in memory and does not spill immediately to disk.
Catalyst Optimizer
Spark DataFrames — built on top of Spark SQL — get their performance speeds using an underlying catalyst optimizer. Catalyst optimizer finds the most efficient ways to apply your transformations and actions. Catalyst optimizer is the reason why the DataFrames have better performance than RDDs (Spark’s native API).
Whenever we run a query using Spark SQL (it can be DataFrame code in PySpark as well), it undergoes several planning stages before converting into a physical plan and getting executed. Using Dataframes and Spark SQL means that you rely on a catalyst optimizer to optimize your query plan instead of using RDDs and doing it yourself. For example:
### For example, you are trying to calculate the average salary of employees by age
### using RDDs
filed = sc.textFile(“/employeeData.csv”)
filed.map( x => {val fields = x.split(",") \
(fields(1), fields(2)) }) \
.map(x => (x._1, (x._2, 1))) \
.reduceByKey((x,y) => (x._1 + y._1, x._2 + y._2))\
.map( x => (x._1, x._2._1 / x._2._2))
### using Dataframes
data_df = fileRdd.toDF(“username”, “age”, “salary”)
data_df.groupBy($”age”).agg(avg(“salary”))
In the RDD approach:
We are telling Spark exactly how to do using Lambda functions, and Spark can’t optimize that. It directly sends those functions to executors to work on the data. If there’s any possible optimization, we have to do it ourselves.
In DataFrame approach:
We are using the declarative way in which we are telling Spark what to do and leaving the how-to-do part on Spark’s optimizer. This makes DataFrames’ optimization possible via catalyst optimizer.
Catalyst Optimizer Working
When we submit a query using Spark SQL, it undergoes the following steps.
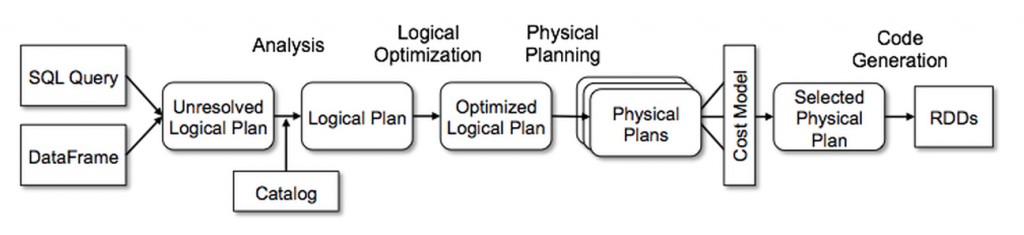
Figure 5: Catalyst Optimizer working (Image courtesy: Databricks blog)
- It creates an unresolved logical plan and checks for the validity of column names and table names etc.
- After that, a resolved logical plan is created. At this step, commands might get reorganised to optimize performance.
- The catalyst optimizer might generate at least one physical plan at this stage to execute the query. This stage represents what Spark will actually do after optimizations have been applied.
- In the case of more than one physical plan, the cost for each plan is evaluated using a cost model. Plan with the best performance is selected, compiled to Java bytecode, and executed.
Caching
Spark can store data in memory during computations. This is a great way to speed up queries even further. We know that Spark is an in-memory processing engine, but it has to read data once from a disk before starting the processing e.g.,
data_file = spark.read.csv(“/home/users/some_random_data.csv”)
This is the first read from disk, and every lineage this read is a part of will have to read it from disk. But you can store this in memory to speed up your processing using caching.
df_cached = Data_file.cache()
df_persisted = Data_file.persist()
cache() and persist() are built-in Spark functions for in-memory storage. cache() only stores to the default value (MEMORY ONLY); however, persist has several options e.g. MEMORY and DISK persistence.
You can do the same for any data that is frequently accessed in your application logic. In applications that reuse the same datasets repeatedly, caching is one of the most powerful optimization techniques. When you cache a DataFrame, each of its partitions will be temporarily stored in the memory of its executor, which will make upcoming reads faster.
Lifecycle of a Spark Application
We have covered the core components of a Spark application. Let’s have a look at the lifecycle of an application itself. Assume that you created a PySpark application my_first_app.py and submitted it to the cluster.
spark-submit \
--master yarn \
--deploy-mode cluster \
--conf <some_key> = <some_value> \
my_first_app.py
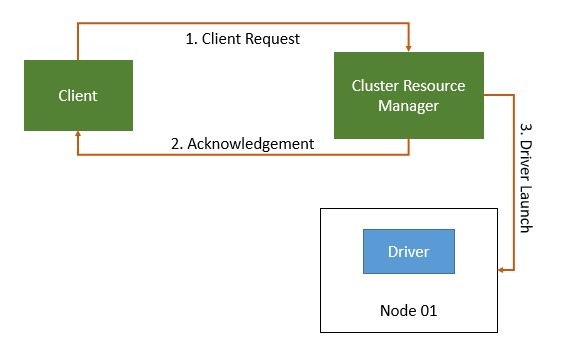
Figure 6: Spark Application: Launching driver program
First, this application will communicate with the resource manager and ask for resources to run. If that request is successful, the Driver program is initiated on one of the nodes (Figure 6). As this is a packaged application, the first thing in the code should be created on SparkSession.
Once the SparkSession is created, it communicates with the cluster manager asking to launch Spark executor processes across the cluster. Keep in mind that several executors and relevant configurations (cores, RAM, etc.) are set by the user when submitting the application.
Cluster manager responds to request by launching executor processes and sends the relevant information to the driver process. After that, the driver and executors communicate, move data around, and the driver schedules tasks onto each executor (Figure 7). Each executor responds with status (success or failure) and the result.
In Figure 7, we have three nodes in total. On Node 01, the driver process is running. On Worker 01, two executors are running, while Worker 02 has only one executor process running.
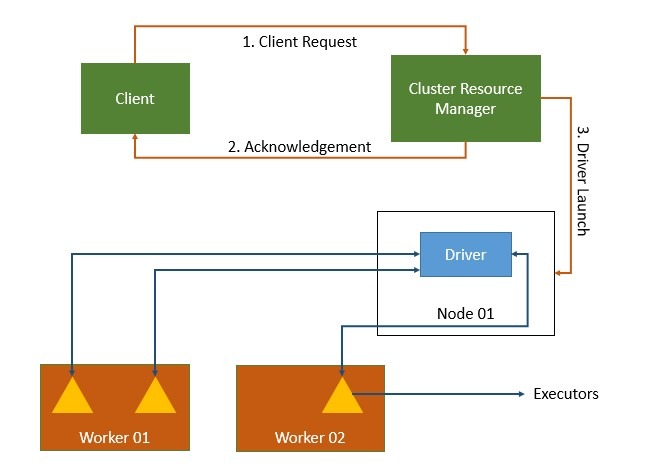
After the completion, the driver exits with success or failure, and the cluster resource manager shuts down the executors in the cluster.
The actual code that you wrote in my_first_app.py defines your Spark application, and each application can have one or more jobs.
In general, there’s one Spark job for one action. A Spark job is broken down into series of stages. Stages represent a group of tasks that can be executed together, e.g., a Select followed by a Where, etc. Whenever data is needed to be shuffled among executors (e.g., in JOIN queries), Spark creates a new stage. Each stage consists of several tasks that run in the available slots on executors.
Summary
We have covered the basic architecture and lifecycle of an Apache Spark application. A typical Spark application consists of a driver and multiple executors. The driver program is the brain of a Spark application. It orchestrates the application lifecycle through multiple executors. The secret to Spark’s performance is parallelism, i.e., the ability to assign work to multiple virtual machines.
Spark does not execute operations as soon as they are encountered in code (lazy evaluation). Instead, it builds up a plan for data transformations that will be applied to your source data. That plan is executed only when you call the action.
To optimize the code execution, Spark has a built-in tool called Catalyst Optimizer. It is designed to find the most efficient plan for applying the transformations and actions to your data. Spark’s in-memory processing, parallel execution, and wide range of built-in functionalities make it one of the fastest data processing engines that exist today.
Quick Link
You may like

Why SWIFT ISO 20022 is reshaping the future of payments
Discover how SWIFT ISO 20022 is transforming financial messaging with richer data, faster wire tr
READ MORE