Connected Lakehouse: The future of modern data warehousing & analytics
Written by: Eraj Mehmood & Ammar Afzal (Data & AI Competency)
November 25, 2021
Many enterprises are investing in the next generation of data-related solutions, hoping to democratize data at scale to get actionable insights and ultimately make automated intelligent decisions.
The value of advanced analytics has already become one of the strategic priorities for every futuristic enterprise. While data warehouses or data lakes are considered essential in any business strategy, they also have common failure points that lead to unfulfilled promises at scale. To address these challenges, enterprises are always ready to move from the centralized paradigm of data lakes or their predecessor data warehouses towards more advanced solutions.
The data lakehouse is becoming a new norm to counter advanced data-related challenges. So, what is a Data lakehouse? Simply, it's a cross between a data warehouse and a data lake.
We can define a connected lakehouse as a construct that aims to enable a unified Data Fabric to modernize and simplify our data ecosystem practices without compromising performance and security. Connected Lakehouse will bring collaboration across data consumer personas and enable a contextual semantic layer for ease of use and access.
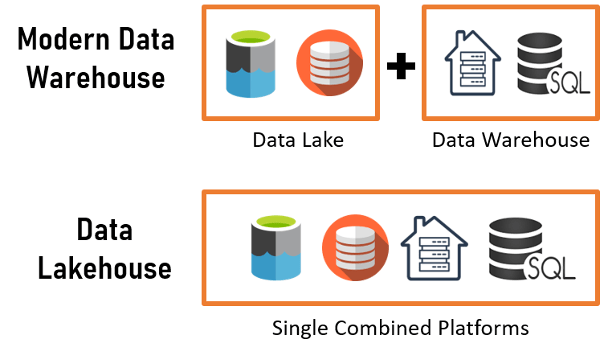
Figure 1: Comparison of modern data warehouse and data lakehouse approaches
Data lake limitations & warehouse uncertainties
Data warehouses were the first generation of rational databases, but as the need and demands of data-related activities increased, they became obsolete with time. While appearing to be the next best possible solution after data warehouses, data lakes carry their related challenges, including:
Data warehouses were the first generation of rational databases, but as the need and demands of data-related activities increased, they became obsolete with time. While appearing to be the next best possible solution after data warehouses, data lakes carry their related challenges, including:
- Data reprocessing: Missing or corrupted data becomes a problem for traditional data lakes that need reprocessing. In case of data access failure, the data engineer has to remove this mission or corrupted data. This tedious reprocessing of data increases the cost and time properties.
- Data validation: Missing or minimal data validation leads to poor data reliability. This data reliability problem can arise at critical times, sometimes breaking the data pipelines.
- Batch & steaming data: Exponential data growth demands enhanced data ingesting capacity; data lakes must have the built-incapacity to manage streaming and batch data types efficiently. Solution architects often turn towards "Lambda Architecture" for batch and streaming data ingestion simultaneously. The Lambda Architecture further needs two codes for streaming and batch processing, along with two separate data repositories (data warehouse & data lake in most cases). This practice leads to development overheads, costs for setting up two data repositories, and increased maintenance overheads.
- Update, merge and delete: Lack of mechanism to ensure data consistency, data updates, merges, and data removal becomes a burden for companies, becoming pain points in meeting data regulations like the CCPA and GDPR.
Limitation for AI & ML
- Data swamps: Many of the data lakes' promises aren't fulfilled due to the lack of valuable features like limited data quality and governance support. So, as a result, data lakes often become data swamps. Data Swamps are badly designed, poorly documented, and inadequately managed data lakes.
- Data cleansing: Data cleansing is one of the most valuable elements of data processing. However, within the context of data lakes, only essential data cleansing can be achieved. As logical and rational data cleansing demands schema information and the data in data lakes is stored in heterogeneous files.
The evolution of data warehousing
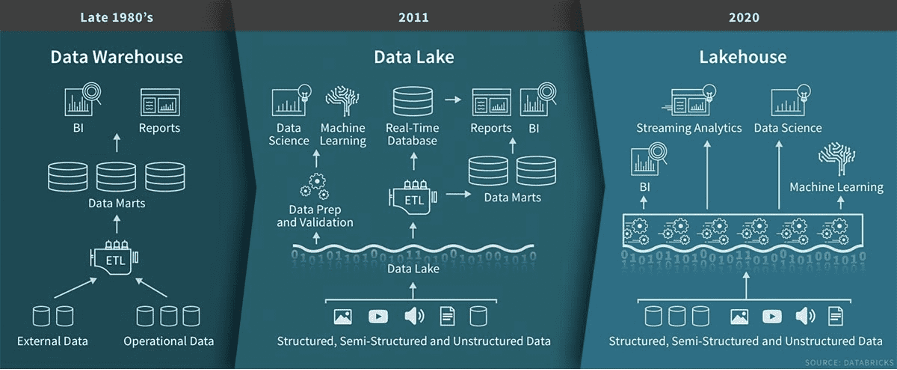
Figure 2: Image via Databricks
- The early days of data management systems: Relational Database Management System (RDBMS) was the foundation of Data Warehousing. The analytical infrastructure of a data warehouse is composed of an ETL, Data Model, Metadata, Data Lineage, and summarization. Enterprises can fetch data insights with only highly structured data using Structured Query Language (SQL).
- The data lake: To handle extensive data volumes, data lakes emerged. The data is stored in raw format and is available as per business requirements. Data lakes store data in the cloud, making it a cost-effective storage system. Data lakes also answered the problem of silos found in data warehousing.
- The data lakehouse paradigm: The latest innovation, lakehouse's prime goal is to unify the key features of data warehouses and data lakes. The Lakehouse is enabled by open system design, implementing similar data structures and management as in data warehousing. The Lakehouse can merge the value of data lakes and data warehousing, so the teams can move faster as they can access data without multiple systems.
Data warehouse, data lake, and data lakehouse – A comparison
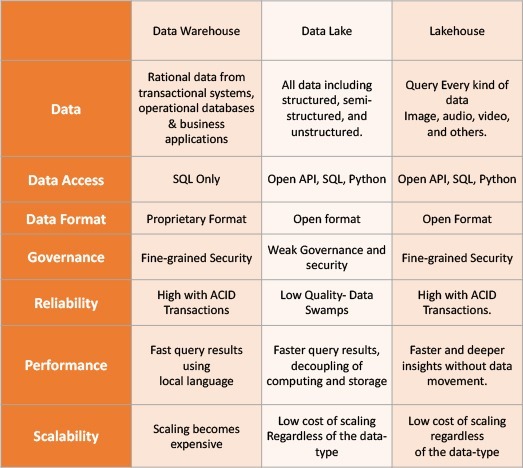
The architecture of the Data Lakehouse
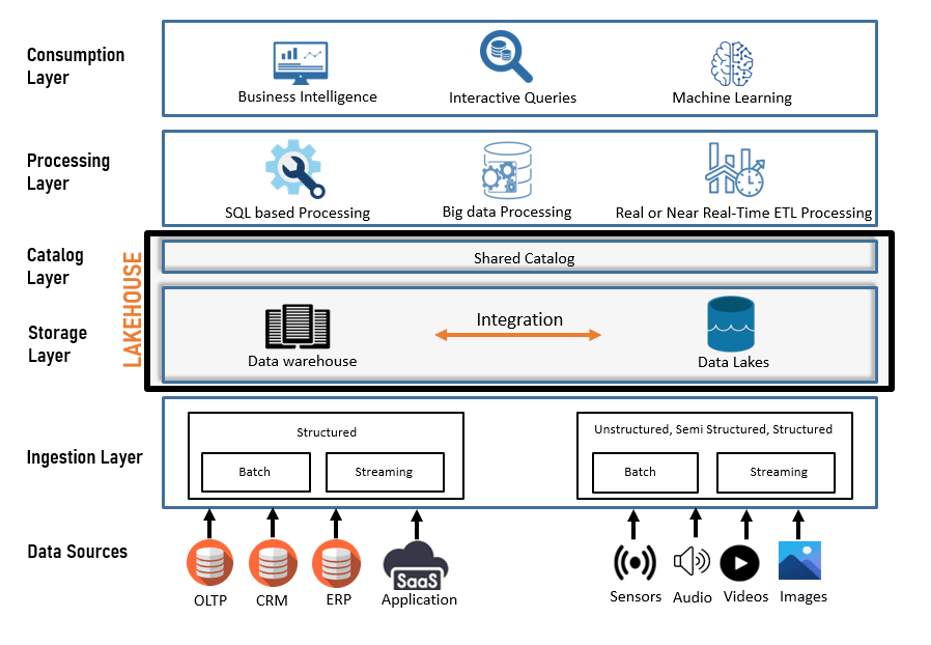
Figure 3: High-level data lakehouse architecture & flow
In the lakehouse architecture, the data lake and data warehouse are natively integrated to present a unified data platform for data processing and consumption. The lakehouse processing and consumption layers then consume all the extracted data; stored in the storage layer. Within a single unified lakehouse interface, users don't have to move between the data lake and the data warehouse to access data.
Key features of the Lakehouse
The lakehouse architecture takes the existing data lakes one step further and seeks to combine the benefits of both the data warehouse and the data lake. A lakehouse architecture has several advantages, including:
- Built-in transactional support: The lakehouse architecture supports ACID (atomic, consistent, isolated, durable) transactions and provides low-cost, faster updates, deletes, and schema enforcement. Built-in support for ACID transactions ensures consistency.
- Schema enforcement and governance: Enforcing the schema more effectively promotes data integrity and governance. A lakehouse architecture supports the creation of schema models. Schema evolutions allow users to edit/change the data while protecting data integrity.
- Fast BI support: A lakehouse provides faster BI support by allowing the BI tools to query the data directly. This eliminates the need for a separate copy of data in a reporting layer, specifically for BI reporting tools.
- Diverse data sources: The lakehouse architecture supports almost all the data sources, including structured, semi-structured, and unstructured data. It can efficiently store, refine, and analyze any data type, including images, text, video, and audio.
- End-to-end streaming: Lakehouse supports real-time streaming and eliminates the need for separate pipelines dedicated to serving real-time data.
- Machine learning: The exponential growth of data has accelerated the scale of machine learning. That is why it is now crucial to have a robust platform to support ML capabilities. The lakehouse architecture provides faster data versioning, which data scientists can utilize during AI/ML model building.
- Low cost of ownership: Lakehouse Architecture is dedicated to providing cost-effective services while constantly innovating to improve data processing and accuracy. The total cost of ownership is lower as compared to traditional versions.
Building a lakehouse – Available tools
- Google BigQuery (BQ)
Google BigQuery (BQ) is a fully managed data warehousing tool from the Google Cloud Platform (GCP). BigQuery (BQ) enables organizations to follow the data lakehouse architecture. Most organizations have started their journey towards data lakehouse using Google BigQuery (BQ).
- Apache Drill
Apache Drill is one of the best querying engines to build a robust data lakehouse architecture. It joins cross-format queries like JSON and CSV by a single query. Only, the data cleansing takes extra time. But once data cleansing is completed, then querying with Apache Drill becomes simplified.
- Delta Lake
Databricks Delta Lake is an open-source lakehouse storage layer. The Delta Lake helps to leverage the processing power of the Lakehouse. It also enables ACID transactions, and metadata handling, and unifies stream and batch data processing.
Bottom Line
The latest data warehousing advancements will surely wither the existing data architecture. The recently emerged concept of Lakehouse is a low-cost solution with open and direct data access, extended ML support, and state-of-the-art overall performance.
Overall, the lakehouse architecture is a well-designed, modern solution for efficient data processing. By combining the power of Lakehouse architecture and self-service data management skills, organizations can dramatically improve productivity and fetch informed business insights efficiently. For more information get in touch with our experts.
Quick Link
You may like



How can we help you?
Are you ready to push boundaries and explore new frontiers of innovation?